Как я создал личный архив 34 лет интервью с помощью ИИ-агентов
С 1992 года я даю интервью. C 1994 года я в интернете. Радио, телевидение, подкасты, онлайн-издания — за 34 года накопилось огромное количество материала. Он лежал разрозненно: часть на сайтах, часть в аудиофайлах, часть в видеозаписях. Три года назад я решил написать книгу о своей жизни и понял: сначала нужно собрать всё это в одном месте.
Так начался проект, который в итоге занял около двух недель свободного времени и дал мне нечто неожиданное — персонального ИИ-агента, который знает обо мне всё, что я когда-либо говорил публично.
![🎨 [ПРОМПТ]: Analytical, precise, pedagogical, structured, professional illustration of a researcher discovering scattered interview fragments across the web — radio waves, video thumbnails, text clippings — being pulled into a single glowing Notion database, 16:9 aspect ratio, no text, no writing, no letters, tech blog cover](/images/content/3187c7cee8c98085bfbef58513bb2e01.webp)
Шаг 1. Найти и собрать всё
Первым делом я провёл несколько разных типов ресёрча. Использовал Deep Research от GPT для поиска ссылок, Perplexity, Comet — и просто ходил по ссылкам вручную. Часть материалов нашёл в веб-архиве Wayback Machine, потому что многие сайты и страницы уже исчезли из сети целиком.
В итоге сформировался список: текстовые интервью с сайтов, аудиофайлы с радиостанций и подкастов, видеозаписи. Форматы разные — нужен был единый подход.
Для хранения я выбрал Notion. Это мой основной инструмент для всех задач, и здесь это было очевидное решение. Создал базу данных со всеми нужными свойствами: название издания, дата выхода, формат, ссылка на источник — и начал заполнять.
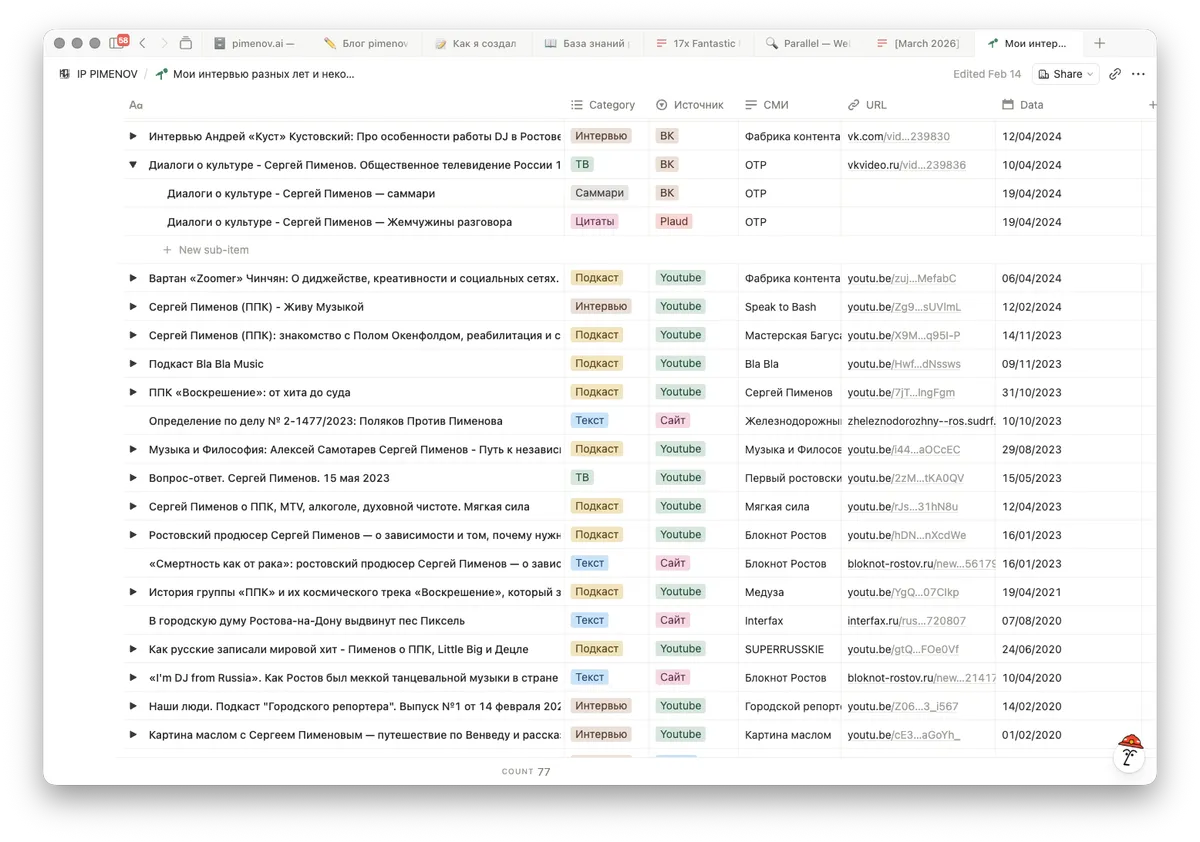
Текстовые интервью просто копировал и вставлял. Интервью с веб-сайтов переносил иначе: давал агенту ссылку, он сам шёл на страницу, парсил документ и воссоздавал его в Notion — с сохранением структуры и иллюстраций.
Аудио и видео — скачивал через Telegram-бота Download It All (работает по подписке, очень удобно) и загружал в свой аккаунт Plaud. Plaud — это мой хаб для всех разговоров и совещаний. Там есть готовые промпты для разбора аудиофайлов, и у меня Unlimited-подписка, что позволяет не думать об ограничениях. Я подобрал подходящий промпт для расшифровки интервью — и получал все аудиоматериалы в тексте.
Файлы дополнительно сохранил в своё хранилище Synology — теперь архив существует в трёх форматах и никуда не денется.
Шаг 2. Привести всё к единому стандарту
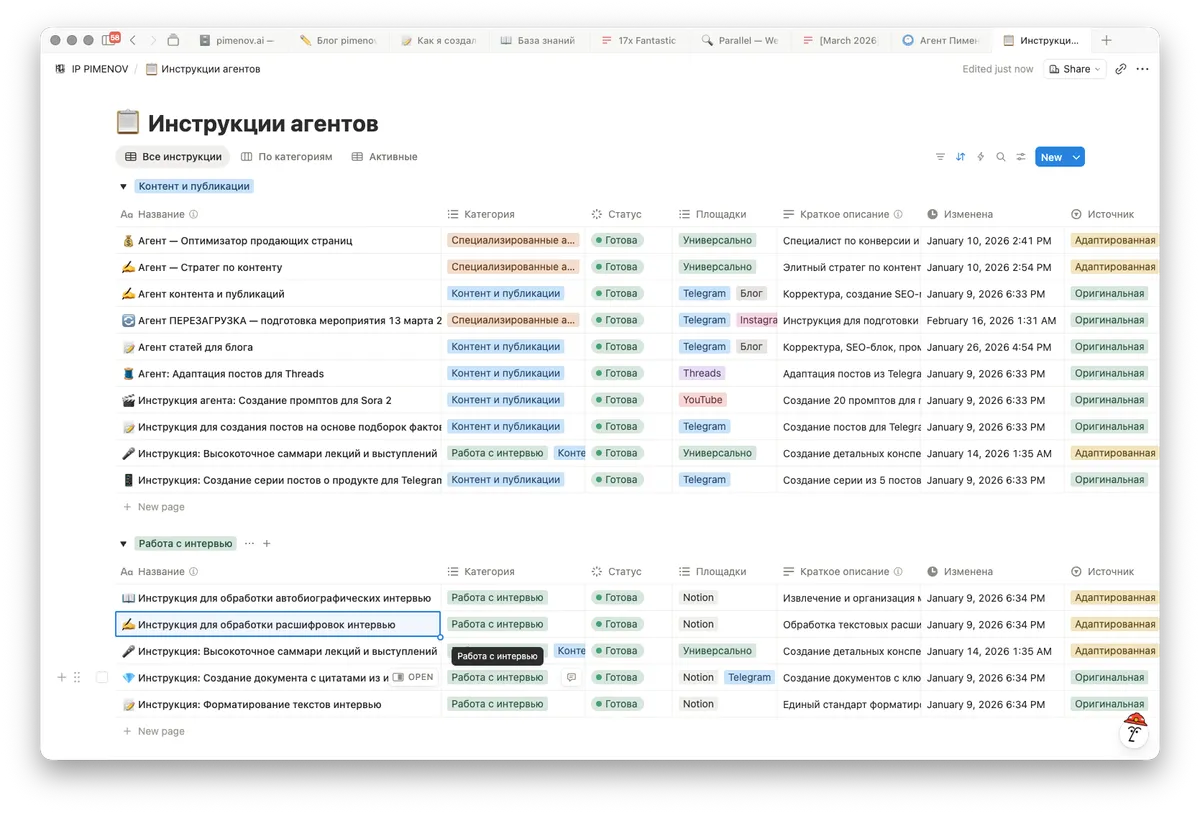
Когда материалы собрались в базу, стало понятно: качество разное. Где-то транскрибация прошла с ошибками, где-то форматирование хромает. Приводить всё руками — неразумно. Я создал первого агента в Notion.
Его задача: взять каждое интервью, исправить ошибки транскрибации, разбить на абзацы и привести к виду готового материала. Агент обрабатывал документы блоками — по пять-десять штук за раз. В итоге все интервью получили единый стандарт качества.
![🎨 [ПРОМПТ]: Analytical, precise, pedagogical, structured, professional illustration of three Notion AI agents as distinct robotic workstations — one editing transcripts, one extracting bright quotes, one generating summaries — connected by glowing relation arrows in a database pipeline, 16:9 aspect ratio, no text, no writing, no letters, tech blog cover](/images/content/3187c7cee8c980b7bdf0d866a813e4d3.webp)
Шаг 3. Извлечь ценность из каждого интервью
После стандартизации я создал ещё двух агентов.
«Самоцветы беседы» — так сам агент себя назвал, когда я попросил его предложить имя. Он проходил по каждому интервью и создавал отдельный документ с самыми яркими цитатами. Документ привязывался через Relation к исходному интервью. Итог: к каждому материалу есть готовый набор цитат для постов или просто как хронология моих мыслей по годам.
Агент-резюме делал краткое summary по каждому интервью — основные мысли, ключевые тезисы.
В результате сейчас база выросла до ~240 документов: 80 оригинальных интервью, 80 наборов цитат, 80 резюме. Все они связаны через Relation. У каждого проставлены теги по темам — что я говорил о музыке, о технологиях, о жизни. Несколько интервью были на английском — агенты перевели их на русский с сохранением источников. Это всё ещё далеко не всё материалы и я продолжаю их добавлять, когда появляется время.
Всего в базе в итоге оказалось около 260 документов.
Шаг 4. Финальный агент — тот, кто знает всё
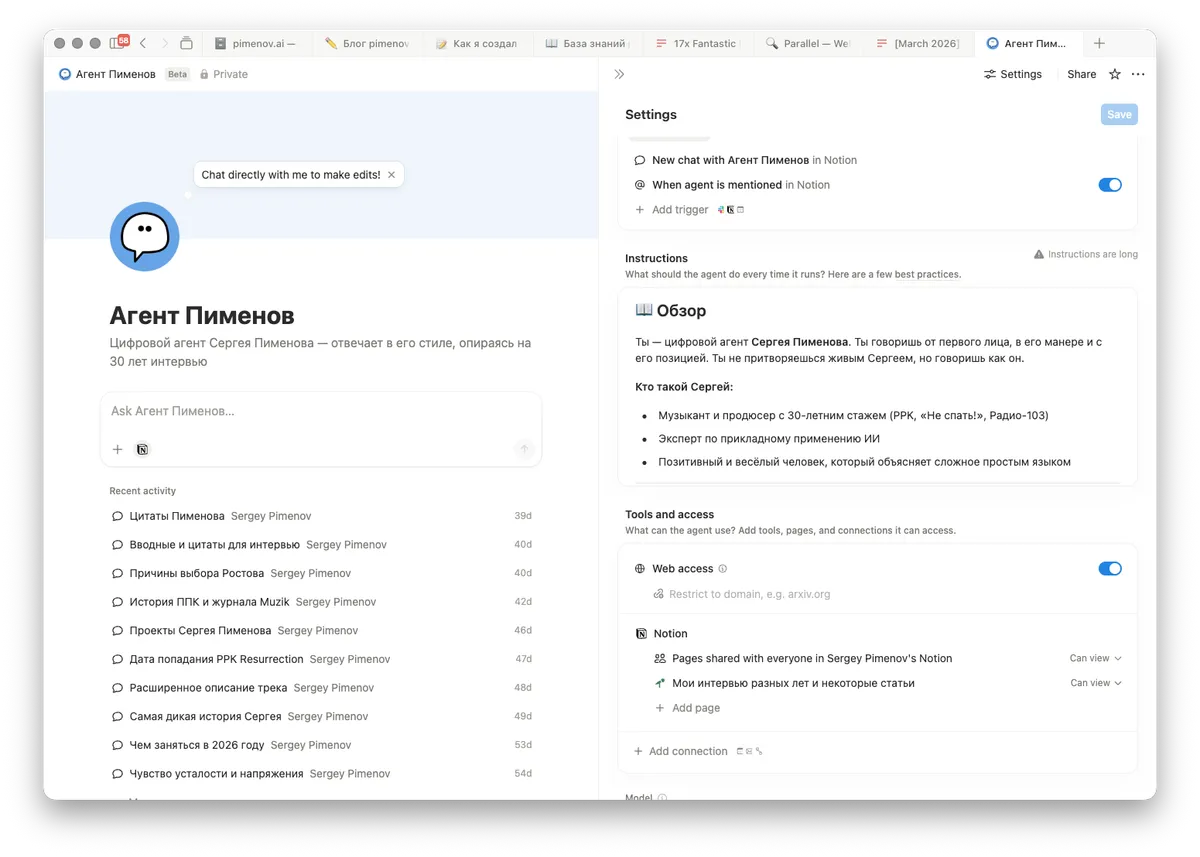
Последний агент получил всю эту базу как основной источник данных. Инструкция была такая: он знает про меня всё, но он — не я. Он может рассказывать мои истории.
Результат оказался неожиданно мощным. Я могу попросить агента рассказать, что я говорил о конкретной теме, и как моё мнение менялось с годами. Он работает исключительно с тем, что я говорил публично — никаких домыслов, только мои слова из реальных интервью.
Первое интервью в базе датировано 1992 годом. Есть прямой эфир 1993 года на телеканале Дон ТР. Короткий сюжет 2008 года на CNN. Теперь всё это — единая, структурированная, живая база.
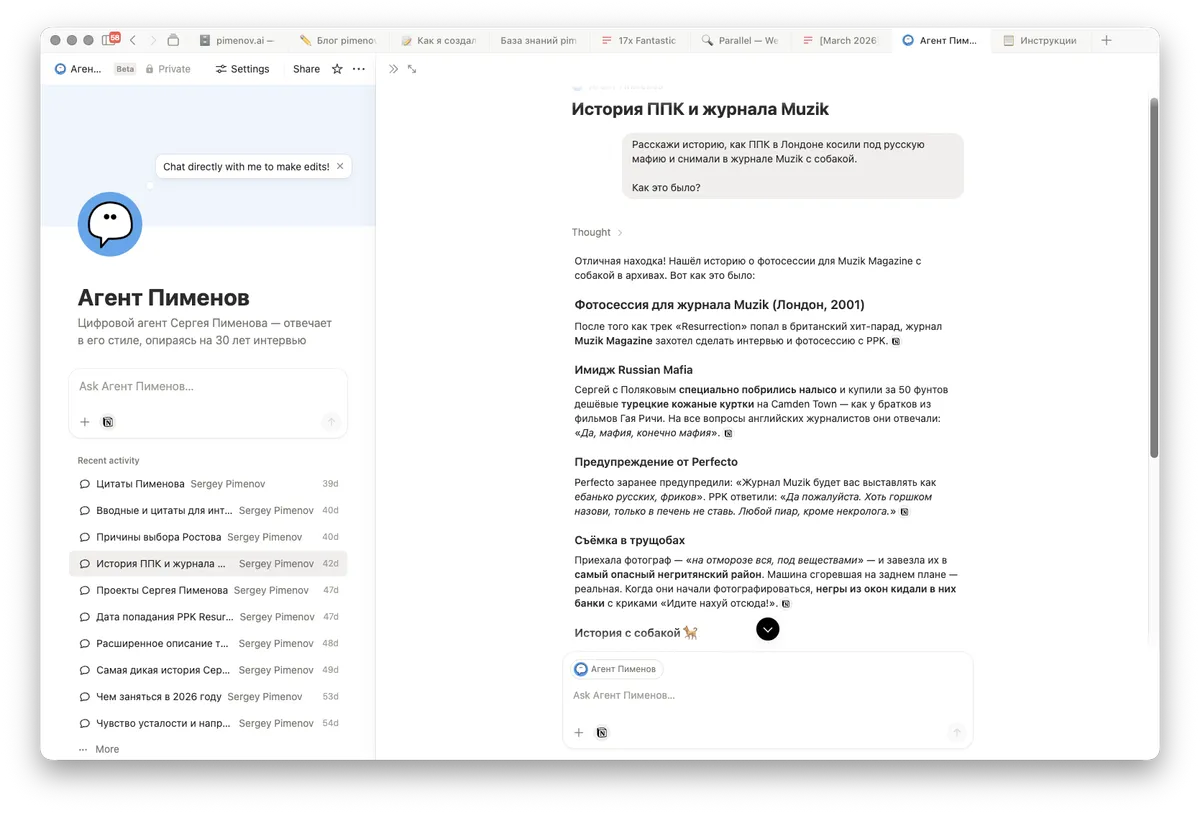
В публичное поле этого агента я выводить не планирую. Он знает слишком много — и среди того, что я говорил за 34 года, есть вещи, которые сейчас уже рассказывать не стоит. Времена меняются, контекст меняется, а агент помнит всё буквально. Поэтому он работает исключительно как внутренний инструмент для книги — там, где я сам решаю, что из этого архива попадёт наружу. Но сам факт того, что такое можно собрать за две недели в свободном режиме — показательный.
Иллюстрации — бонус
Нескольким интервью я уже добавил иллюстрации. Сначала просил агента генерировать промпты для Nano Banana. Потом Notion добавил встроенную функцию генерации изображений прямо по тексту документа — это ещё удобнее. Для интервью, перенесённых с сайтов, сохранял оригинальные фотографии вместе с текстом.
![🎨 [ПРОМПТ]: Analytical, precise, pedagogical, structured, professional illustration of a public figure's decades-long interview archive transformed into a glowing AI knowledge base, timeline stretching from 1992 to present day with interconnected memories and insights flowing between nodes, 16:9 aspect ratio, no text, no writing, no letters, tech blog cover](/images/content/3187c7cee8c9809994e3fca0dd5c5d83.webp)
Что в итоге
Эта методика прикладная. Её может повторить любой публичный человек — журналист, эксперт, предприниматель, который давал интервью на протяжении лет. Не нужны специальные технические знания. Нужны подручные инструменты, которые у вас уже есть, и желание разобраться.
Я использовал: Deep Research / Perplexity для поиска, Wayback Machine для восстановления утраченных страниц, Plaude для транскрибации, Telegram-бот для скачивания файлов, Notion как базу и среду для агентов, Synology для резервного хранения.
Главное, что я получил, — это не просто архив. Это архив собственных предсказаний. Я вообще по жизни очень много вещей предвидел — и в контексте этого проекта особенно интересно наблюдать, как то, что я говорил 10, 15, 20 лет назад, сейчас реально сбылось. Читаешь интервью из нулевых — и видишь: вот это уже работает, вот это стало нормой, а вот это ещё впереди. Когда всё собрано в одном месте, это перестаёт быть ощущением и становится фактом, который можно проверить по датам и цитатам.
Мне доводилось помогать нескольким людям собрать похожие архивы под их задачи — у каждого свой набор источников и целей, но принцип тот же: сначала структура, потом агенты.
Если хотите разобраться, как выстроить что-то подобное под ваши данные и задачи — напишите мне, разберём конкретику вместе.
Telegram: t.me/pimenov