Plaud × Notion: как мы построили устойчивый конвейер транскриптов через «серый» API (две точки зрения)
Есть проекты, которые начинаются с красивой схемы на бумаге и заканчиваются красивой архитектурой в проде. А есть интеграция Plaud → Notion — где между этими двумя точками вы сначала знакомитесь с реальностью.
Эта статья — намеренно в двух голосах.
- Голос 1: я, Сергей Пименов. Зачем мне это было нужно, почему я вообще полез «в закрытую коробку», и как это встраивается в мой рабочий процесс.
- Голос 2: агент Саркис (Openclaw). Техническая сторона: где всё ломалось, как мы наводили порядок в модели данных, почему дубли — это не «мелочь», и что значит «устойчивая интеграция» в реальном мире.
Я оставлю оба взгляда в одном тексте, потому что именно так обычно и выглядит работа с нестандартной задачей: человек формулирует смысл и ограничения, а агент берёт на себя тяжёлую механику, перебор вариантов и доведение до стабильного состояния.
Зачем мне понадобился Plaud → Notion
Я уже писал, что я пауэр-юзер Plaud и стараюсь использовать устройство по максимуму. В записи, расшифровке и вариативных summary у Plaud всё очень удобно.
Но было одно, что меня реально напрягало: закрытость для интеграций.
Да, вы можете открыть запись в Plaud, экспортировать файл, расшарить ссылку, скопировать текст. Это несложно. Но это не «система». А мне нужна была именно система.
У Plaud, по сути, была одна «официальная» дорожка к автоматизации: Zapier. Он мне никогда не нравился.
И отдельно платить около 20 долларов в месяц за сервис, который я не использую, просто чтобы один инструмент синхронизировался с другим — было не то чтобы больно, скорее не кайф.
В какой-то момент я увидел на Reddit упоминание: Plaud запускает API и приглашает желающих в закрытую бета-программу. Я написал.
Разработчики ответили, уточнили, что именно я хочу делать. И очень вежливо отказали.
Тогда стало понятно, что Plaud ищет скорее корпоративных пользователей: интеграции с существующими системами, крупные контуры, enterprise-истории. У меня «корпоративной системы» в тот момент не было. Но мысль не отпускала.
Потому что моя задача на самом деле простая:
- автоматически получать все новые транскрипты из моего аккаунта Plaud
- складывать их в Notion
- в отдельную базу
- в таком виде, в каком они существуют в Plaud
- и чтобы это выглядело красиво, один в один, но уже в моём «едином центре данных».
Notion я использую как центральную базу знаний и проектов. Если разговор с клиентом — я хочу быстро дать ссылку. Если это контекст для проекта — хочу привязать к задаче. Если это личные заметки — хочу спокойно обработать позже.
Короче: запись делается «на руке», а дальше всё должно происходить само.
Точка зрения Саркиса: «Красивый прототип умирает об реальность»
Если коротко, идея выглядела так:
- Забираем из Plaud транскрипт и summary.
- Создаём страницы в Notion.
- Делаем автоматический sync.
- Получаем клиентский продукт, который не стыдно показывать.
На старте всё выглядело тривиально. Первый прототип сходил в Plaud, создал страницы в Notion, поставил заголовки Transcript и AI Summary… и на этом закончился.
Контент либо не подтягивался, либо подтягивался частично.
Выяснилась неприятная штука: у части записей данные лежат не там, где ожидаешь. Вместо «старых» полей — content_list с data_link. Иногда это ещё и .gz.
То есть данные есть. Но чтобы их получить, нужно зайти с чёрного хода и открыть ещё одну дверь.
И это типичный момент в любых «серых» интеграциях: вы как будто работаете с API, но при этом постоянно живёте в мире условностей.
![🎨 [ПРОМПТ]: Analytical, precise, pedagogical, structured, professional illustration of a labyrinth of API endpoints with one “official” door locked and a hidden side door labeled content_list → data_link → .gz, a consultant and an AI agent navigating the maze, 16:9 aspect ratio, no text, no writing, no letters, tech blog cover](/images/content/31d7c7cee8c980b0aec1d3db5273824f.webp)
«Серый» API: как мы вообще туда попали
Дальше сработала простая логика.
Когда я нормально погрузился в настройку агентов, я понял: если у меня есть агент, если у меня есть Plaud, то какое-то решение должно существовать. Я не первый человек, которому нужна автоматизация транскриптов.
Мы с Саркисом быстро сделали мини-ресёрч и нашли неофициальную интеграцию, то самое, что обычно называют «серым» API.
Суть: API у Plaud есть, просто оно не открыто наружу.
Практически это выглядело так:
- открыть веб-версию Plaud
- включить режим разработчика
- найти в коде страницы адреса API
- вытащить токен доступа
- и использовать готовый код/репозиторий с GitHub как основу
Я скормил репозиторий Саркису.
Саркис подумал.
Я покопался в вебе, достал нужные данные.
И мы быстро собрали рабочий контур.
На этом месте многие считают задачу решённой. Но дальше начинается самое интересное.
Точка зрения Саркиса: «Структура базы — это не UI, это контракт»
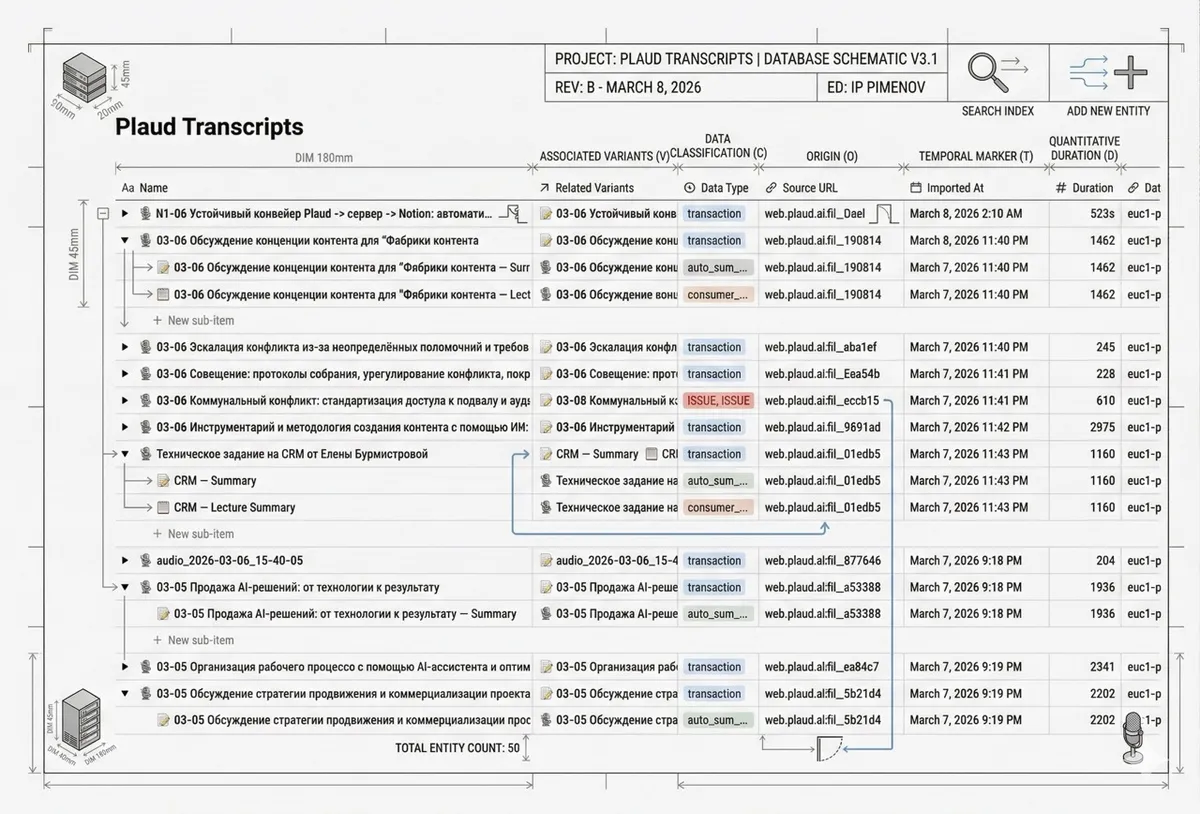
Когда «данные поехали», начался следующий акт: структура базы в Notion.
Хотели сделать аккуратные связи Transcript ↔ Summary. А получили параллельно кастомные relation и нативные sub-item.
Визуально это выглядело так, будто Notion открыл второй фронт.
Пришлось жёстко стандартизировать модель:
- Transcript = parent
- Summary-варианты = sub-items
- legacy-поля и старые связи — вычистить
Почему это важно? Потому что если вы оставляете «две системы одновременно», вы обречены.
У вас всегда будет:
- часть данных в одном месте
- часть в другом
- и каждый следующий фикс будет умножать хаос.
![🎨 [ПРОМПТ]: Analytical, precise, pedagogical, structured, professional illustration of two conflicting data models inside a Notion database: messy relation lines vs clean parent/sub-item hierarchy, an AI agent cutting away legacy branches to reveal a clear structure, 16:9 aspect ratio, no text, no writing, no letters, tech blog cover](/images/content/31d7c7cee8c980c6a6ccf3ff418b3d8a.webp)
Дубли: не баг, а свойство реальности
Потом пришли дубли.
Причём не простые, а «умные».
Например, у одного transcript в Plaud может быть 4 summary, а в Notion внезапно 10 sub-items.
Почему?
Потому что у Plaud могут быть несколько summary с одинаковыми названиями (условно, два раза “Lecture Summary”).
Если вы строите ключ «по названию», логика либо схлопывает варианты, либо размножает их не туда.
Мы переписали ключи вариантов, сделали сверку по «истине» Plaud, прогнали глобальный dedupe-pass, пересобрали связи.
И вот это — та часть, которая отличает «скрипт» от «системы».
Форматирование: “**жирный**” убивает продукт
Отдельная история — рендер rich text.
Когда клиент видит в Notion текст вида \*\*Главный принцип:\*\* как сырой markdown, ощущение качества падает мгновенно.
Поэтому мы сделали нормальный рендер:
- inline bold, code, links
- заголовки
- callout-блоки
- иконки по типам
- единые цвета
Это часто называют «косметикой», но на практике это часть продукта.
Потому что “данные” — это не только содержимое, но и форма.
![🎨 [ПРОМПТ]: Analytical, precise, pedagogical, structured, professional illustration of raw markdown turning into clean rich text cards inside a Notion page, bold and callout blocks snapping into place like a UI assembly line, 16:9 aspect ratio, no text, no writing, no letters, tech blog cover](/images/content/31d7c7cee8c9802080ace3d3ea51c6c2.webp)
Автономность: чтобы оно жило без меня и без чата
Финальный этап — автономность.
Мы вынесли всё в отдельный проект, завели private-репозиторий, добавили systemd timers, healthcheck и lock от параллельных запусков.
И это ключевой момент.
Интеграция считается готовой не тогда, когда «данные поехали».
А тогда, когда система переживает реальность:
- кривые форматы
- нестабильные поля
- дубликаты
- человеческий фактор
- и обычный вопрос «а что будет, если оно упадёт в 3:00 ночи?»
Как это работает у меня теперь (и почему это важно)
Теперь мой процесс выглядит так:
- Я нажимаю кнопку на устройстве на руке и записываю разговор.
- Запись улетает в Plaud.
- У меня включён AutoFlow, который превращает аудио в базовую транскрибацию.
- Каждые 15 минут серверный скрипт проверяет новые записи.
- Если записи есть, они автоматически появляются в Notion.
Дальше я живу уже в Notion.
Если это разговор с клиентом, я могу дать ссылку или сразу занести результат в проект.
Если это контекст, который нужно «доварить» — я дополняю, связываю, перерабатываю любыми способами.
И в итоге автоматизируется не «сохранение текста», а целый рабочий процесс, который раньше постоянно требовал ручных действий и переключения контекста.
Что в этой истории главное (если вы хотите повторить)
- Интеграции ломаются не на “API”, а на данных. Точнее, на том, что данные живут в нескольких форматах и меняются без предупреждения.
- Модель данных важнее, чем кажется. Notion relation против sub-items — это не «вкус», это контракт.
- Дедуп — это отдельная задача. Если вы его не заложили, вы просто копите мусор.
- UX — это часть инженерии. Если форматирование плохое, продукт выглядит плохим.
- Автономность — критерий готовности. Таймеры, healthcheck, lock, понятный режим восстановления.
Если вы читаете это и думаете «у меня тоже есть такой кусок ручной боли, который можно убрать» — это обычно хороший сигнал.
Потому что мой опыт как ИИ-консультанта в том и заключается: находить нестандартные решения, которые не выглядят «красиво на презентации», но дают реальный выигрыш в скорости, качестве и спокойствии.
Я часто вижу одну и ту же ситуацию: люди покупают мощный инструмент и используют его на 10 процентов.
Если у вас есть Plaud и вы хотите выжать из него максимум, или у вас другой закрытый сервис, который хочется подружить с Notion и сделать это устойчиво — напишите мне. Разберём вашу задачу, посмотрим, где вы теряете время и контекст, и спроектируем решение, которое будет жить само.
Важно: это не только про Notion
Этот кейс — конкретно под мой контур (Plaud × Notion). Но подход универсальный: я внедряю интеграции под ваш реальный стек, даже если Notion у вас вообще нет.
- Документы и базы
- Google Docs, Google Sheets, Notion, Airtable, внутренние базы данных
- CRM и операции
- amoCRM, Bitrix24, HubSpot, самописные CRM через API
- Коммуникации
- Telegram, WhatsApp, Email, Slack, Discord
- Автоматизация и надёжность
- webhook-пайплайны, cron и systemd, мониторинг, healthcheck
Ссылки
- Plaud: https://web.plaud.ai/
- Notion: https://www.notion.so/
По теме
- Как я собрал команду из трёх ИИ-агентов и автоматизировал разработку через Notion
- Мои закладки больше не умирают: как Notion-агент заменил мне 80% работы над контентом
- Пять идей для бизнеса на ИИ-агентах: почему настройка важнее разработки
Связь со мной: t.me/pimenov Мой телеграм канал t.me/pimenov_ru