Programmatic SEO 2.0: как один маркетолог создал 13 000 страниц за 3 часа и вырастил трафик на 466%
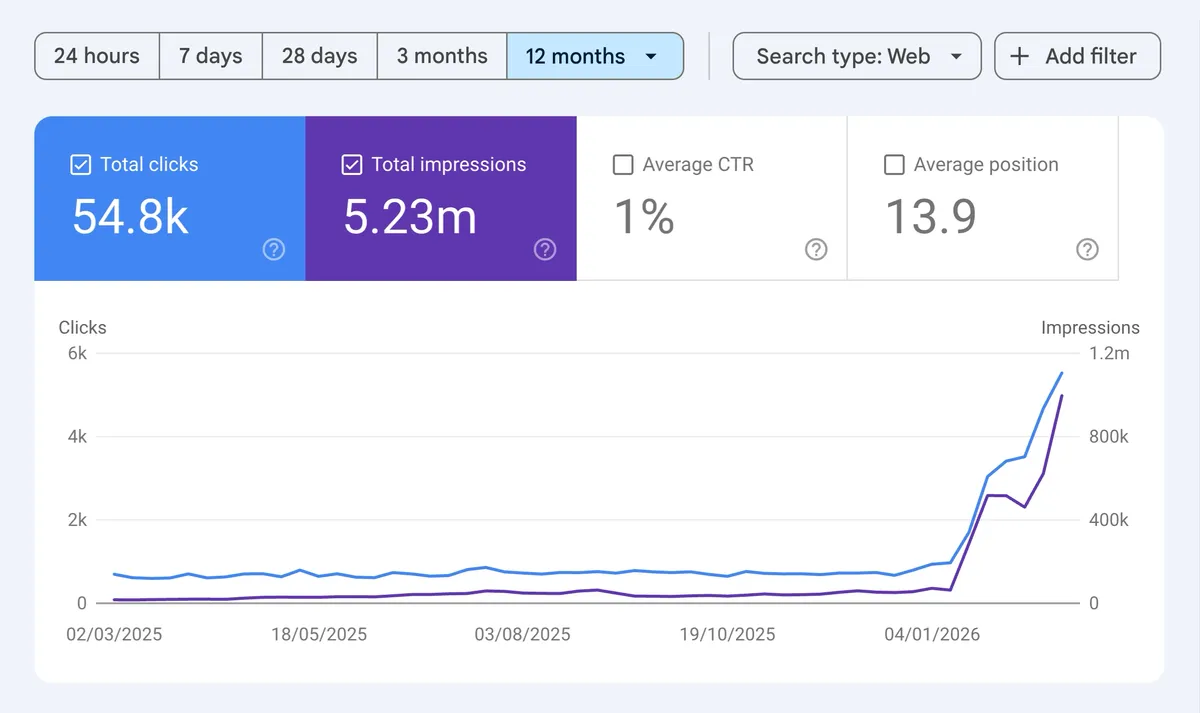
60 дней назад страниц, которые сейчас приносят основной SEO-трафик сайту Byword, просто не существовало.
Сегодня:
- 13 000+ программно сгенерированных страниц в продакшене
- Еженедельные органические клики выросли с 971 до 5 500
- +466% (в 5,7 раза) рост трафика за 60 дней
- Около 50% страниц ещё даже не проиндексированы
Никакого шаблонного спама, никаких подстановок названий городов, никакого тонкого AI-контента. Вместо этого — система, в которой контент не пишется страница за страницей. Он собирается как софт.
Почему это не обычный pSEO
Когда большинство людей слышат «программатический SEO», они представляют:
- Топ-листы
- Локационные страницы
- Страницы сравнений
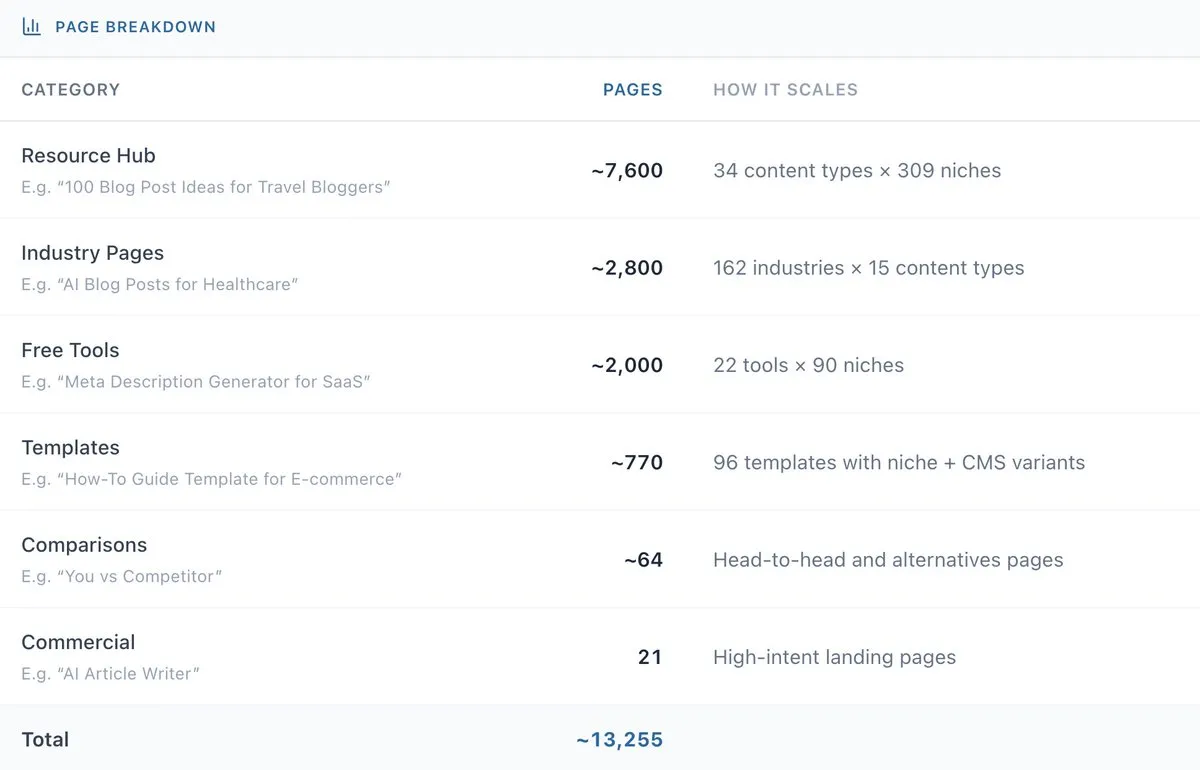
Джейк пошёл значительно шире. Система сгенерировала 13 000+ страниц в шести категориях контента:
- Ресурсные страницы — основная масса (идеи для постов, чек-листы, календари, гайды, шаблоны). 34 типа контента × 309 ниш = 7 600+ страниц
- Бесплатные инструменты — не просто текстовые страницы, а рабочие утилиты с нишевыми примерами
- Гайды по AI-контенту — руководства по использованию ИИ в конкретных нишах
- Шаблоны для pSEO — готовые структуры для программатического SEO
- Альтернативы продуктам — структурированные сравнения
- Страницы сравнений — всего 1% от общего числа (хотя обычно с них начинают)
Страницы сравнений оказались самой маленькой категорией. Те самые «очевидные» ходы, с которых обычно начинают pSEO-практики, принесли наименьший результат.
🎨 [ПРОМПТ]: Analytical, precise, pedagogical, structured, professional illustration of six interconnected content category nodes radiating from a central hub, each node containing different content types like checklists tools and guides, 16:9 aspect ratio, no text, no writing, no letters, tech blog cover
Ключевая идея: JSON-схемы вместо свободной генерации
Если вы вынесете из этого кейса только одну мысль, пусть будет эта:
Для программатических страниц ИИ никогда не просят писать свободный текст. Его просят заполнить строгую JSON-схему.
Как это работает:
- Нишевый контекст — 309 ниш с описанием аудитории, болей и стратегий
- Gemini Flash — заполняет строгие JSON-схемы контентом, адаптированным под нишу
- Валидированный JSON — 13 000+ типобезопасных файлов
- 20+ рендереров — специализированные React-компоненты для каждого типа контента
ИИ генерирует данные, фронтенд отвечает за подачу. Эти два слоя никогда не смешиваются.
Почему это принципиально? Свободная генерация ломается на масштабе:
- Непредсказуемая структура
- Нестабильное качество
- Невозможность валидации
Схемы решают эту проблему, потому что каждая страница следует одной и той же структуре. На выходе: единообразный UX, предсказуемое качество и надёжная генерация в масштабе.
Когда вы генерируете 13 000 страниц, структура — не ограничение. Это условие работоспособности.
Нишевая таксономия — самая важная часть системы
Настоящий масштаб обеспечивает не модель, а нишевая таксономия.
Джейк построил структурированный контекст для 309 ниш, каждая из которых включает:
- Описание аудитории
- Ключевые проблемы
- Стратегии монетизации
- Форматы контента, которые работают
- Ключевые подтемы
Когда система генерирует, например, «SEO-чек-лист для travel-блогеров», она не просто подставляет слово «travel» в общий шаблон. Модель получает полный контекст ниши: аудиторию, боли, стратегии.
В результате чек-лист для health-блогера фокусируется на E-E-A-T, сигналах авторитетности и YMYL-требованиях. А чек-лист для travel-блогера — на сезонном планировании ключевых слов и конкуренции по направлениям.
Та же схема, совершенно другое содержание.
На таксономию было потрачено больше времени, чем на всё остальное. Именно богатый нишевый контекст превращает программатический SEO из шаблонной подстановки в полезный контент в масштабе.
Как устроена генерация
Сама система генерации удивительно проста.
Модель — Gemini Flash. На таком масштабе важнее не пиковое качество модели, а соотношение цены и качества. Gemini Flash поддерживает нативный структурированный JSON-вывод — модель возвращает валидный JSON напрямую, без обёрток в текст или markdown. Это устраняет целый класс проблем с парсингом.
Система запускает 100 параллельных воркеров. API-лимиты — единственное реальное узкое место. При таком уровне параллельности полный корпус из 13 000+ страниц генерируется менее чем за 3 часа.
Важная деталь: заголовки не генерируются ИИ. Вместо этого используются детерминистические шаблоны вроде: «100 идей для постов в блог для travel-блогеров в 2026 году». На практике хорошо спроектированный шаблон даёт лучшие заголовки, чем ИИ.
Разделение контента и дизайна
Ещё одно архитектурное преимущество:
- Контент = JSON
- Дизайн = React-компоненты
Можно полностью переделать дизайн сайта, не перегенерируя ни одного файла с контентом. Джейк уже несколько раз обновлял макеты страниц — ни один контент-файл не изменился.
Каждый тип контента имеет собственный специализированный рендерер:
- Страницы с идеями для постов — фильтрация по категории и сложности
- SEO-чек-листы — интерактивные чекбоксы
- Сравнения инструментов — структурированные таблицы
Всего 20+ целевых компонентов, и все потребляют один и тот же структурированный JSON.
Результаты за 60 дней
Страницы раскатывались прогрессивно в течение нескольких недель с мониторингом индексации и трафика.
Итоги:
- 13 000+ страниц в продакшене
- +466% рост трафика (в 5,7 раза)
- ~50% страниц проиндексировано (пока)
- <3 часов — время полной генерации
С каждой новой партией проиндексированных страниц они ранжируются по long-tail запросам в течение дней и добавляют инкрементальный трафик.
Ключевые наблюдения:
Ресурсные страницы принесли больше всего трафика. Идеи для постов, SEO-чек-листы и контент-гайды — основная масса трафика. Информационные запросы в масштабе: высокий объём, низкая конкуренция.
Бесплатные инструменты показали лучший engagement. Люди используют инструмент, а затем исследуют остальной сайт. Другой интент, другая часть воронки.
Индексация — главное узкое место. Только ~50% страниц проиндексировано, а значит, система ещё не раскрыла и половины потенциала.
Никаких негативных сигналов от Google. Страницы индексируются чисто, ранжируются по заслугам и держатся. Обновления Google «helpful content» их не затронули.
Почему Google это не наказывает
Когда люди слышат «13 000 AI-сгенерированных страниц», первая реакция предсказуема: «Это же именно то, что Google наказывает?»
Но эта система работает иначе.
Страницы — не просто текст. Страница «100 идей для постов в блоге для финансовых блогеров» включает структурированные разделы, фильтрацию по категории и сложности, функцию копирования. Страницу можно реально использовать.
Каждый тип контента имеет свой React-компонент. Фильтрация, поиск, структурированные таблицы, нормальный UX, Schema markup, breadcrumbs, FAQ schema. Это не markdown-страницы, вставленные в общий шаблон.
Тест, который Джейк применяет к каждой странице:
- «Была бы эта страница полезной, если бы поисковых систем не существовало?»
- «Если кто-то добавит страницу в закладки и вернётся позже — она всё ещё будет полезной?»
Для большинства этих страниц ответ — да.
Традиционный pSEO обычно проваливает этот тест: подстановка переменных в шаблон, одинаковый контент с разными названиями городов. Тысячи страниц, которые технически существуют, но не несут ценности.
Здесь же схемы обеспечивают полноту, нишевый контекст создаёт релевантность, а компоненты — рабочий UX.
Сайт: что это за страницы
Эксперимент проводился на сайте Byword — AI-инструменте для генерации контента. В начале 2026 года команда перестроила продукт с нуля, и одним из главных результатов перестройки стала описанная система.
Примеры страниц:
- 100 Motorcycle Blog Name Ideas
- AI Content for E-Commerce
- Paragraph Rewriter Tool
- Programmatic SEO Templates for Travel
- Best SEOwriting.ai Alternatives
Чему учит этот кейс
Несколько выводов, которые я считаю применимыми далеко за пределами SEO:
Начинайте с таксономии. Нишевый контекст — фундамент. Джейк рекомендует тратить на него ~60% времени. Это справедливо для любого проекта с контентом в масштабе.
Разнообразьте типы страниц. Страницы сравнений казались очевидным выбором, но оказались самой маленькой категорией. Ресурсные страницы и инструменты принесли основной трафик.
Раскатывайте партиями. Прогрессивный запуск позволяет отслеживать индексацию и вносить корректировки до масштабирования.
Используйте нативный JSON-вывод. Структурированные ответы устраняют проблемы парсинга и делают генерацию в масштабе надёжной.
Инвестируйте во фронтенд. Целевые компоненты — это то, что делает программатические страницы действительно полезными.
Главное — не количество страниц. 13 000+ звучит впечатляюще, но реальное преимущество — в петле обратной связи. Каждую неделю система учится: какие ниши работают лучше, какие типы контента привлекают трафик, где живёт long tail. Эти данные улучшают таксономию, а таксономия улучшает следующий раунд генерации.
Система становится лучше по мере масштабирования.
Мой комментарий
Мне этот кейс нравится по одной простой причине: он показывает, что ИИ работает лучше всего в рамках ограничений.
Не свободная генерация текста, а заполнение структурированных систем, спроектированных людьми. Контент, который не пишется, а собирается.
Это ровно тот подход, который я продвигаю в своих проектах: чёткие схемы данных, разделение генерации и подачи, структура вместо «напиши мне что-нибудь». Работает для SEO, работает для документации, работает для любого контента в масштабе.
По теме
- Статья: Когда ИИ зальёт нас контентом: что останется от искусства и авторства
- Блог: Как строить AI-first SaaS в 2026: два принципа, с которых начать
- База знаний: Action-Based Workflow Engine: архитектурный паттерн
Если вы строите контентные системы или хотите разобраться, как ИИ может масштабировать ваш контент без потери качества — давайте обсудим.
Связь со мной: t.me/pimenov Мой телеграм канал t.me/pimenov_ru