Режим работы
Автосинк
Серверный контур регулярно проверяет новые записи и переносит их в Notion без ручного копипаста.
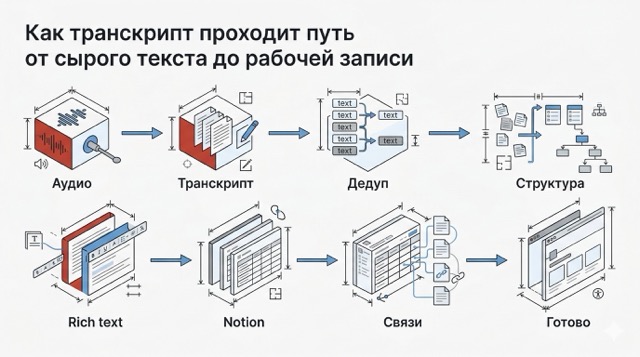
Этот проект начинался не как большая архитектурная история, а как очень практическая задача: перестать терять ценность в транскриптах и сводках, которые копятся быстрее, чем успеваешь их разобрать. Хотелось не просто перенести данные из Plaud в Notion, а собрать контур, в котором записи, summaries и структура базы живут предсказуемо и не рассыпаются после первых же десятков файлов.
Поэтому кейс получился не про «подключили интеграцию и забыли», а про реальную инженерную доводку. Мне пришлось отдельно разруливать дубли, пересобирать связи между сущностями, править структуру базы и смотреть на UX как на часть самой системы. В итоге получился устойчивый конвейер транскриптов, а не красивая схема на один показ.
Режим работы
Автосинк
Серверный контур регулярно проверяет новые записи и переносит их в Notion без ручного копипаста.
Критичный слой
Дедуп + структура
Стабильность здесь держится не на одном запросе к API, а на правильной модели данных и сверке по исходной записи.
Критерий готовности
Автономно
Контур считается готовым, когда переживает кривые форматы, дубли и ночные падения без постоянного ручного присмотра.
Задача
Мне нужна была не просто выгрузка текста из одного сервиса в другой. Нужна была система, в которой запись делается «на руке», а дальше транскрипты и summaries оказываются в моём рабочем центре данных без ручной возни.
Внутри Plaud мне нравились запись, расшифровка и вариативные summary. Но экспорт по одному файлу, ручное копирование текста и постоянные переходы между сервисами — это не система, а серия повторяющихся действий.
Если разговор связан с проектом, клиентом или заметкой, мне важно быстро дать ссылку, связать запись с задачей и продолжить работу уже внутри единой базы, а не держать знания по разным закрытым коробкам.
Инженерный контекст
Это не главный headline кейса, но без этого инженерного слоя история была бы нечестной. Официальная дорожка автоматизации меня не устраивала, а потребность в рабочем sync-контуре никуда не исчезала.
У Plaud была скорее закрытая логика доступа к интеграциям и путь через Zapier, который не решал мою задачу так, как хотелось: предсказуемо, полно и без лишней прослойки между источником и моей базой.
Я опирался на веб-версию Plaud, найденные API-эндпоинты, токен доступа и готовую техническую основу из открытого репозитория. Это дало старт, но не дало готовую систему — дальше началась настоящая доводка.
Разбор реальности
На старте всё выглядело просто: забрать transcript и summary, создать страницы в Notion, включить автоматический sync. На практике система быстро показала, что данные живут в нескольких форматах и не обязаны лежать там, где ты их ожидаешь.
У части записей контент лежал не в старых полях, а внутри content_list с data_link, а иногда ещё и в gzip-варианте. Формально данные есть, но путь к ним совсем неочевидный.
Первый рабочий прототип умел создавать страницы и заголовки, но сам контент приезжал неполно или не приезжал вовсе. То есть витрина была, а продукта ещё не было.
Как только данные поехали, вскрылась следующая проблема: смешение legacy relation-полей и нативной иерархии sub-items внутри Notion. Две модели рядом быстро начинают умножать хаос.
Один transcript мог иметь несколько summary с одинаковыми названиями. Если строить ключи по названиям, система либо схлопывает варианты, либо плодит лишние сущности не туда, куда нужно.
Архитектурное решение
Главный перелом здесь произошёл не на уровне UI, а на уровне контракта данных. Пока база допускает две параллельные логики, каждое следующее исправление только увеличивает хрупкость.
Я стандартизировал основную запись как parent-сущность, вокруг которой строится остальная структура. Это убрало двусмысленность в том, что считать главным объектом в базе.
Вместо смешения кастомных relation и параллельных связей я привёл summaries к нативной иерархии Notion. Так модель стала читаемой и для системы, и для человека.
Старые поля и переходные связи нельзя было просто «оставить на всякий случай». Пока они существуют рядом с новой схемой, база продолжает расходиться в поведении и отображении.
Здесь было мало просто придумать новую схему. Нужно было пересобрать связи между сущностями, сохранить корректные parent/sub-item отношения и привести базу к одному источнику правды.

Дедупликация
Если в Plaud у одной записи несколько summary-вариантов с одинаковыми названиями, наивная логика ключей быстро ломает порядок. Поэтому дедуп пришлось собирать не по внешней красоте, а по «истине» исходной системы.
Я опирался на идентичность записи в Plaud, а не на красивое имя summary. Именно это позволило отделять реальные варианты от мусора, накопленного предыдущими проходами.
Чтобы не лечить симптомы по одной карточке, я прогнал отдельный проход дедупликации, архивировал лишнее и пересобрал связи так, чтобы итоговая структура совпадала с реальным источником данных.
Одинаковые заголовки summary не означают одинаковые сущности. Поэтому критерии сравнения пришлось делать строже, иначе система продолжала бы плодить неверные совпадения.
UX как часть инженерии
Когда в Notion вместо нормального текста приезжает сырой markdown со звёздочками, качество продукта падает мгновенно. В этом кейсе UX был не украшением после технической части, а частью самой инженерной работы.
Я добавил нормальный рендер для жирного текста, ссылок, заголовков и других блоков, чтобы записи читались как готовый рабочий материал, а не как полуразобранный технический дамп.
Иконки, структура полей и аккуратная иерархия нужны не для красоты ради красоты. Это помогает быстрее понять, что перед тобой: основная запись, summary-вариант или технический шум.
Технические outline-записи не должны конкурировать с основными документами за внимание. Я убрал этот шум из того слоя, который реально используется в работе.
Когда база читается предсказуемо, проще заметить сбой, проверить корректность структуры и доверять системе в ежедневной работе. Поэтому UX здесь напрямую влияет на устойчивость контура.
Критерий готовности
Для меня интеграция считается завершённой не в момент, когда данные однажды поехали. Готовность наступает тогда, когда система живёт без постоянного чата рядом и выдерживает нормальную реальность.
Итог
На выходе у меня получилась не демонстрация на один созвон, а рабочий контур, в котором запись улетает в Plaud, сервер проверяет новые материалы, а дальше я уже живу внутри Notion, не теряя контекст между разговором и дальнейшей работой с ним.
Основная ценность здесь не просто в автоматическом переносе, а в том, что записи и их варианты больше не рассыпаются по разным логикам внутри базы.
Если запись относится к клиенту, задаче или личному исследованию, я не возвращаюсь в Plaud за исходником. Нужный материал уже лежит в моём рабочем центре данных.
После стабилизации контура важным результатом стала именно повторяемость: новые записи проходят тот же путь без постоянной ручной доводки каждой партии данных.
Если где-то есть ручная боль, закрытый сервис и ценный поток данных, часто можно собрать устойчивый рабочий контур — но только если серьёзно отнестись к структуре, дедупу и автономности.
Источник
Если нужен более подробный рассказ про сам ход работы, «серый» API, модель данных, дедупликацию и критерий автономности, лучше открыть исходную статью, на которой основан этот кейс.
Кейсы
Кейс
Миграция из amoCRM в Twenty через аудит, пилот на 50 активных сделках, нормализацию данных и сборку управленческой аналитики.
Открыть →Кейс
Notion как центр управления задачами, где три ИИ-агента закрывают планирование, реализацию и проверку результата.
Открыть →Кейс
Контентный pipeline, где сырьё из Telegram, соцсетей и закладок превращается в черновики сайта через Notion-агента.
Открыть →Я обычно начинаю не с абстрактной интеграции, а с реального процесса: где у вас теряется контекст, на каком шаге появляется ручная рутина и что именно должно жить автономно. После этого можно собрать рабочую систему под ваш стек, а не под универсальную презентацию.