GPT Image — гайд по промптингу для генерации и редактирования изображений
Перевод официального гайда OpenAI Cookbook по промптингу моделей gpt-image: параметры моделей, основы промптинга, сценарии генерации (инфографика, фотореализм, логотипы, реклама, UI, слайды) и редактирования (перенос стиля, виртуальная примерка, композитинг, смена освещения).
Перевод на русский. Технические термины и названия параметров (quality, input_fidelity, size и т.д.) оставлены на английском с пояснениями. Текст промптов переведён, но литеральный текст, который должен появиться на самом изображении, оставлен в кавычках на языке оригинала.
1. Введение
Модели генерации изображений gpt-image от OpenAI созданы для визуала продакшен-качества и хорошо управляемых креативных процессов. Они подходят как для профессиональных дизайн-задач, так и для итеративного создания контента, и поддерживают и высококачественный рендеринг, и сценарии с низкой задержкой (latency).
Ключевые возможности:
Фотореализм высокой точности — естественное освещение, корректные материалы и богатая цветопередача
Гибкий баланс «качество ↔ задержка» — более быстрая генерация на низких настройках, при этом качество выше моделей прошлого поколения
Надёжное сохранение лиц и идентичности при редактировании, для консистентности персонажей и многошаговых процессов
Стабильный рендеринг текста — чёткие буквы, ровный макет и хороший контраст внутри изображений
Сложные структурированные визуалы — инфографика, диаграммы, многопанельные композиции
Точный контроль стиля и перенос стиля (style transfer) при минимальном промпте — от брендовых дизайн-систем до художественных стилей
Сильные знания о реальном мире и рассуждение — точное изображение объектов, окружений и сценариев
Этот гайд показывает паттерны промптинга, лучшие практики и примеры промптов из реальных продакшен-кейсов для gpt-image-2. Это самая способная модель: выше качество изображения, лучше редактирование и шире поддержка продакшен-процессов. Настройка качества low особенно хороша для сценариев, чувствительных к задержке, а medium и high остаются удачным выбором, когда важна максимальная точность.
1.1 Параметры моделей изображений OpenAI
Этот раздел — справочник по моделям из гайда, с фокусом на:
название модели
поддерживаемые значения outputQuality (качество вывода)
поддерживаемые значения input_fidelity (точность сохранения входного изображения)
поддерживаемое поведение size / разрешения
рекомендуемые сценарии использования
Сводка по моделям
По состоянию на 21 апреля 2026 у OpenAI доступны следующие модели изображений.
Модель
outputQuality
input_fidelity
Разрешения
Рекомендуемое использование
gpt-image-2
low, medium, high
Отключён. input_fidelity не работает для этой модели, т.к. вывод и так по умолчанию высокой точности
Любое разрешение, удовлетворяющее ограничениям ниже
Рекомендуемый дефолт для новых проектов. Для максимального качества генерации и редактирования, текстоёмких изображений, фотореализма, композитинга, чувствительных к идентичности правок и процессов, где меньшее число повторов важнее минимальной стоимости.
gpt-image-1.5
low, medium, high
low, high
1024x1024, 1024x1536, 1536x1024, auto
Сохраняйте для уже проверенных процессов на время миграции. Для новой работы предпочтительнее gpt-image-2, особенно когда важны качество, надёжность редактирования или гибкость размеров.
gpt-image-1
low, medium, high
low, high
1024x1024, 1024x1536, 1536x1024, auto
Только для обратной совместимости (legacy). Если начинаете новый процесс или обновляете промпты — переходите на gpt-image-2; оставляйте gpt-image-1 лишь для краткосрочной стабильности на время валидации апгрейда.
gpt-image-1-mini
low, medium, high
low, high
1024x1024, 1024x1536, 1536x1024, auto
Когда главное — стоимость и пропускная способность: массовая генерация вариантов, быстрая идеация, превью, лёгкая персонализация и черновые ассеты, которым не нужна максимальная генерация/редактирование.
gpt-image-2 поддерживает любое разрешение в параметре size при соблюдении всех условий:
Максимальная длина стороны меньше 3840px
Обе стороны кратны 16
Соотношение длинной и короткой сторон не больше 3:1
Всего пикселей не более 8 294 400
Всего пикселей не менее 655 360
Если изображение превышает 2560x1440 (3 686 400 пикселей, т.н. 2K), считайте это экспериментальным — выше этого размера результаты более вариативны.
Удобные ориентиры, укладывающиеся в ограничения выше:
Метка
Разрешение
Заметки
HD-портрет
1024x1536
Стандартный портретный вариант
HD-альбом
1536x1024
Стандартный горизонтальный вариант
Квадрат
1024x1024
Хороший универсальный дефолт
2K / QHD
2560x1440
Популярный широкоформатный размер и рекомендуемая верхняя граница надёжности для gpt-image-2
4K / UHD
3840x2160
Экспериментальная верхняя цель. Если правило макс. стороны трактуется буквально как < 3840, округляйте вниз до ближайшего валидного размера, например 3824x2144
Выбирайте gpt-image-2 как дефолт для большинства продакшен-процессов. Это самая сильная модель и правильная цель апгрейда для команд на gpt-image-1.5 или gpt-image-1.
Выбирайте gpt-image-2 с quality: low, когда решают скорость и юнит-экономика. Этой настройки хватает для многих кейсов, и она хороша для высокообъёмной генерации и экспериментов. Можно попробовать и gpt-image-1-mini, но на практике quality: low работает не хуже.
Оставляйте gpt-image-1.5 или gpt-image-1 только для обратной совместимости, пока валидируете миграцию промптов, прогоняете регресс-тесты вывода или поддерживаете старые процессы.
Переходите на gpt-image-2 для клиентских ассетов, фотореалистичной генерации, процессов с активным редактированием, бренд-чувствительного креатива, работы с текстом в изображении и любых задач, где лучшее качество с первого прохода снижает ручную проверку и повторы.
Рассматривайте gpt-image-1-mini вместо legacy-моделей только когда главная цель — снизить стоимость на больших партиях черновых или менее ответственных изображений.
На время миграции сначала держите промпты почти неизменными, а перенастраивайте только после сравнения качества, задержки и доли повторов на вашей реальной нагрузке.
2. Основы промптинга
Эти основы применимы ко всем моделям генерации изображений gpt-image. Они основаны на паттернах, многократно проявившихся в альфа-тестировании на генерации, правках, инфографике, рекламе, изображениях людей, UI-макетах и композитинге.
Структура + цель: пишите промпт в постоянном порядке (фон/сцена → субъект → ключевые детали → ограничения) и указывайте назначение (реклама, UI-мок, инфографика), чтобы задать «режим» и уровень полировки. Для сложных запросов используйте короткие подписанные сегменты или переносы строк вместо одного длинного абзаца.
Формат промпта: используйте формат, который проще поддерживать. Минимальные промпты, описательные абзацы, JSON-подобные структуры, инструкция-стиль и теговые промпты — всё работает, если намерение и ограничения ясны. Для продакшен-систем предпочитайте читаемый шаблон, а не хитрый синтаксис.
Конкретика + сигналы качества: будьте конкретны про материалы, формы, текстуры и визуальный носитель (фото, акварель, 3D-рендер) и добавляйте точечные «рычаги качества» только при необходимости (например, film grain (плёночное зерно), textured brushstrokes (фактурные мазки), macro detail (макро-детализация)). Для фотореализма вставляйте слово «photorealistic» прямо в промпт, чтобы сильно задействовать фотореалистичный режим модели. Похожие фразы — «real photograph», «taken on a real camera», «professional photography», «iPhone photo» — тоже помогают, но детальные характеристики камеры трактуются вольно, поэтому используйте их в основном для общего вида и композиции, а не для точной физической симуляции.
Задержка против точности: для чувствительных к задержке или высокообъёмных кейсов начинайте с quality="low" и проверяйте, достаточно ли вам визуала. Часто этого хватает при заметно более быстрой генерации. Для мелкого/плотного текста, детальной инфографики, крупных портретов, чувствительных к идентичности правок и высоких разрешений сравните medium или high перед запуском.
Композиция: задавайте кадрирование и точку обзора (крупный план, широкий, сверху), перспективу/угол (на уровне глаз, нижний ракурс) и освещение/настроение (мягкое рассеянное, золотой час, высокий контраст). Если важен макет, прямо указывайте расположение (например, «logo top-right», «субъект по центру с негативным пространством слева»). Для широких, кинематографичных, тёмных, дождливых или неоновых сцен добавляйте больше деталей о масштабе, атмосфере и цвете, чтобы модель не жертвовала настроением ради поверхностного реализма.
Люди, поза и действие: для людей в сцене описывайте масштаб, обрезку тела, направление взгляда и взаимодействие с объектами. Примеры: «full body visible, feet included» (всё тело, со ступнями), «child-sized relative to the table» (размер ребёнка относительно стола), «looking down at the open book, not at the camera», «hands naturally gripping the handlebars». Это помогает с пропорциями тела, геометрией действия и направлением взгляда.
Ограничения (что менять, а что сохранить): явно указывайте исключения и инварианты (например, «no watermark», «no extra text», «no logos/trademarks», «preserve identity/geometry/layout/brand elements»). Для правок используйте «change only X» + «keep everything else the same» и повторяйте список сохраняемого на каждой итерации, чтобы уменьшить дрейф. Если правка должна быть хирургической, добавляйте, что нельзя менять насыщенность, контраст, макет, стрелки, подписи, ракурс камеры и окружающие объекты.
Текст в изображениях: литеральный текст давайте в кавычках или КАПСОМ и указывайте типографику (стиль шрифта, размер, цвет, расположение) как ограничения. Для сложных слов (бренды, нестандартное написание) прописывайте их по буквам, чтобы повысить точность символов. Для мелкого текста, плотных инфопанелей и многошрифтовых макетов используйте medium или high.
Несколько изображений на входе: ссылайтесь на каждый вход по индексу и описанию («Image 1: product photo… Image 2: style reference…») и описывайте их взаимодействие («apply Image 2's style to Image 1»). При композитинге явно указывайте, какие элементы куда переносятся («put the bird from Image 1 on the elephant in Image 2»).
Итерируйте, а не перегружайте: длинные промпты работают, но отлаживать проще, начав с чистого базового промпта и уточняя маленькими однократными правками («make lighting warmer», «remove the extra tree», «restore the original background»). Используйте ссылки вроде «same style as before» или «the subject», чтобы опираться на контекст, но переуказывайте критичные детали, если они начинают дрейфовать.
3. Подготовка (setup)
Запустите один раз. Это:
создаёт API-клиент
создаёт output_images/ в папке изображений
добавляет небольшой хелпер для сохранения base64-изображений
Положите референс-изображения для правок в input_images/ (или поправьте пути в примерах).
import os
import base64
from openai import OpenAI
client = OpenAI()
os.makedirs("../../images/input_images", exist_ok=True)
os.makedirs("../../images/output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""
Сохраняет первое возвращённое изображение в указанный файл в папке output_images.
"""
image_base64 = result.data[0].b64_json
out_path = os.path.join("../../images/output_images", filename)
with open(out_path, "wb") as f:
f.write(base64.b64decode(image_base64))
В примерах ниже используется самая способная модель — gpt-image-2.
4. Сценарии — Генерация (текст → изображение)
4.1 Инфографика
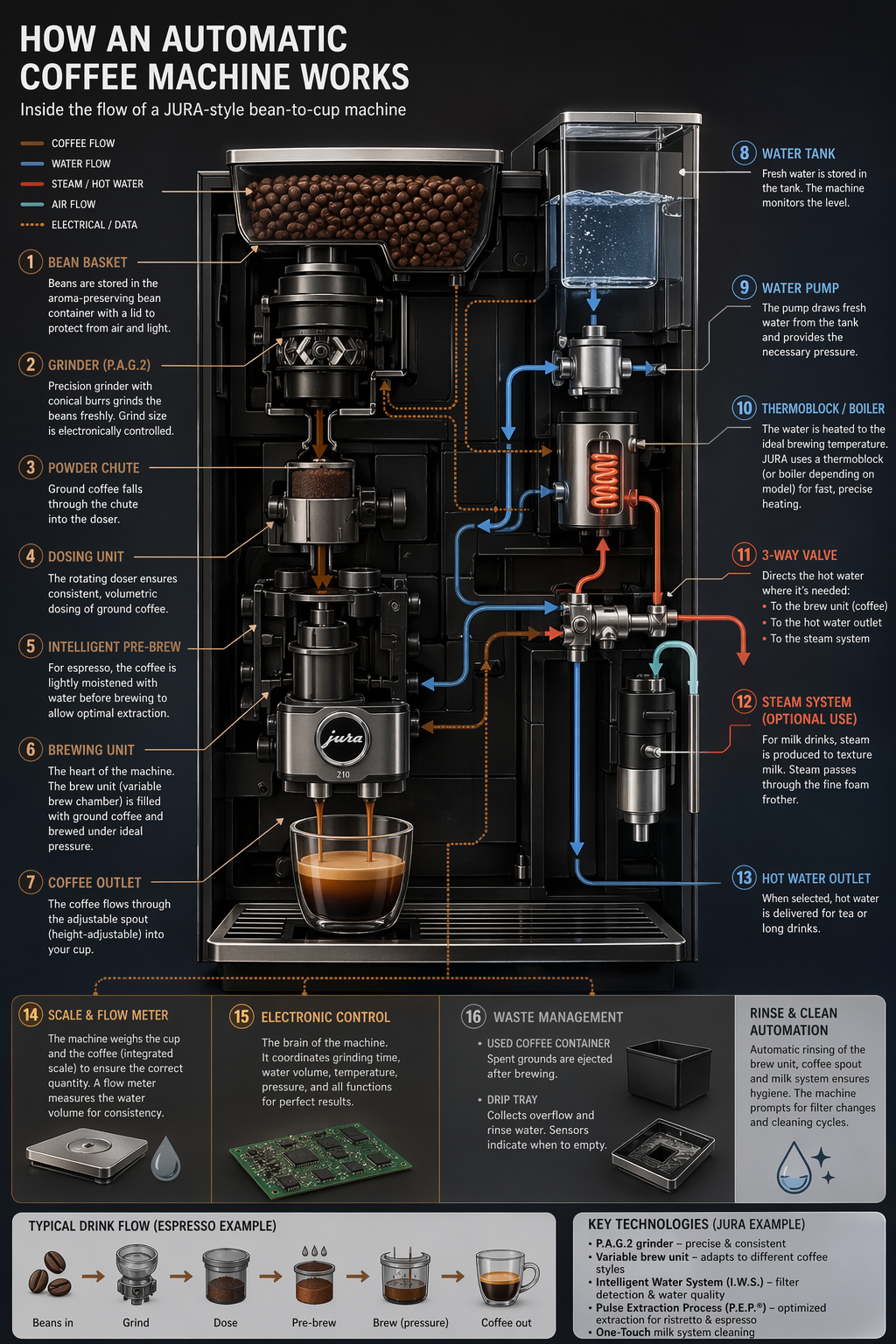
Используйте инфографику, чтобы объяснить структурированную информацию для конкретной аудитории: студентов, руководителей, клиентов или широкой публики. Примеры: объяснялки, постеры, диаграммы с подписями, таймлайны, «визуальная вики». Для плотных макетов и текстоёмких изображений рекомендуется ставить quality="high".
prompt = """
Создай подробную инфографику работы и потока автоматической кофемашины типа Jura.
От бункера для зёрен — к помолу, весам, бак для воды, бойлер и т.д.
Хочу понять технически и визуально весь этот поток.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "infographic_coffee_machine_gpt-image-2.png")
Инфографика работы автоматической кофемашины — gpt-image-2
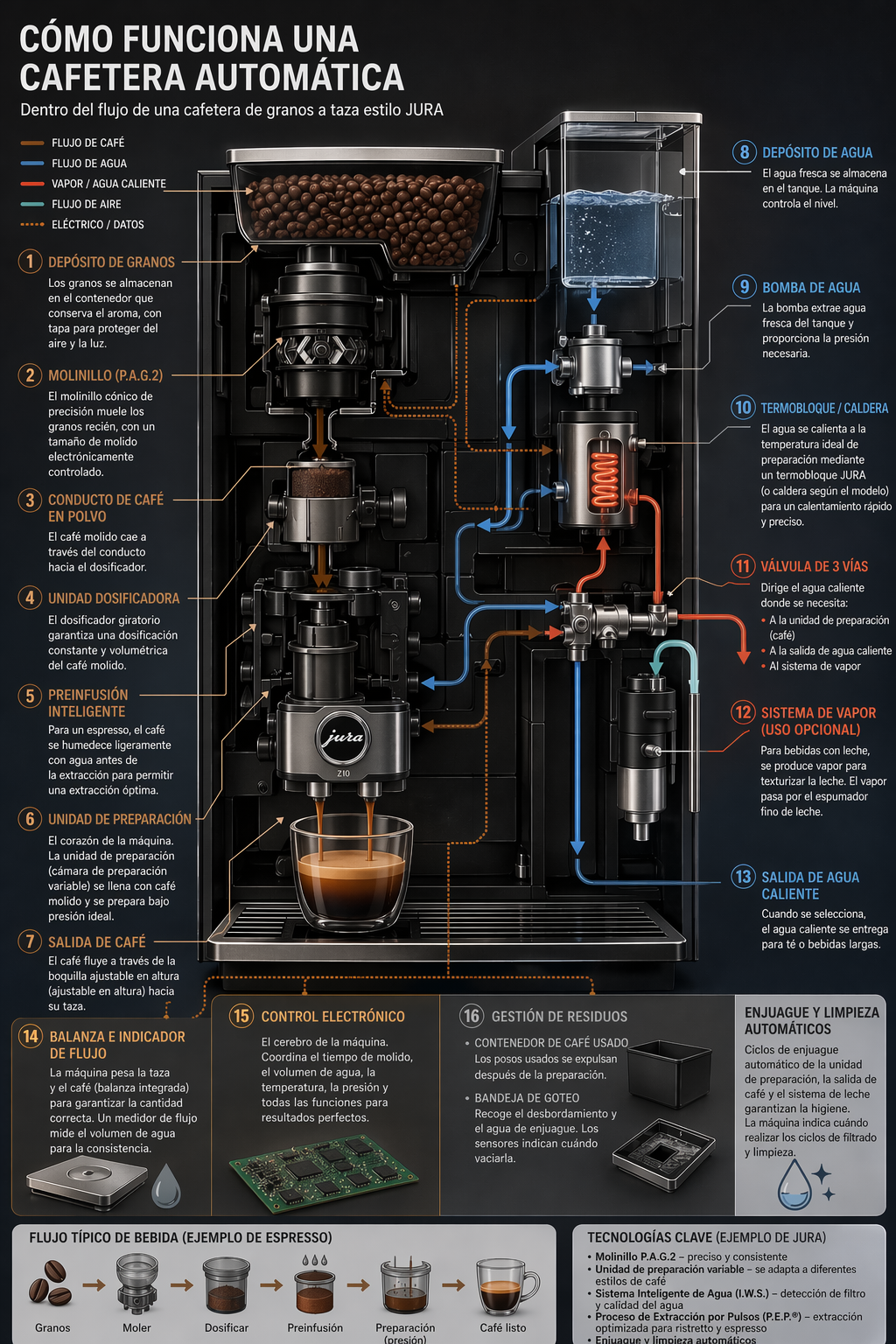
4.2 Перевод текста на изображениях
Используется для локализации готовых дизайнов (реклама, скриншоты UI, упаковка, инфографика) на другой язык без пересборки макета с нуля. Ключ — сохранить всё, кроме текста: типографику, расположение, отступы и иерархию, переводя дословно и точно, без лишних слов, без перекомпоновки (если не нужно) и без случайных правок логотипов, иконок или картинок.
prompt = """
Переведи текст на инфографике на испанский. Не меняй никакие другие аспекты изображения.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/output_images/infographic_coffee_machine_gpt-image-2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "infographic_coffee_machine_sp_gpt-image-2.png")
Та же инфографика с переведённым на испанский текстом — gpt-image-2
4.3 Фотореалистичные «естественные» изображения
Чтобы получить правдоподобный фотореализм, промптите модель так, будто реальное фото снимается прямо сейчас. Используйте фотоязык (объектив, освещение, кадрирование) и явно просите реальную текстуру (поры, морщины, износ ткани, несовершенства). Избегайте слов, намекающих на студийный глянец и постановку. Когда важна детализация, ставьте quality="high".
prompt = """
Создай фотореалистичную (photorealistic) документальную фотографию пожилого моряка, стоящего на небольшой рыбацкой лодке.
У него обветренная кожа с заметными морщинами, порами и следами загара и несколько выцветших традиционных морских татуировок на руках.
Он спокойно поправляет сеть, рядом на палубе сидит его собака.
Снято как плёночная фотография на 35 мм, средний крупный план на уровне глаз, объектив 50 мм.
Мягкий прибрежный дневной свет, малая глубина резкости, лёгкое плёночное зерно (film grain), естественный цветовой баланс.
Изображение должно ощущаться честным и непостановочным — реальная текстура кожи, изношенные материалы, бытовые детали. Без гламуризации, без сильной ретуши.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "photorealism-gpt-image-2.png")
Модели gpt-image сочетают сильное рассуждение со знаниями о мире. Например, при запросе сцены в Бетеле, штат Нью-Йорк, в августе 1969 года, они способны вывести Вудсток и создать точное, контекстно-уместное изображение без явного упоминания события.
prompt = """
Создай реалистичную уличную сцену с толпой в Бетеле, штат Нью-Йорк, 16 августа 1969 года.
Фотореалистично, аутентичные для эпохи одежда, постановка и окружение.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "world_knowledge-gpt-image-2.png")
Уличная сцена в Бетеле, Нью-Йорк, август 1969 (Вудсток) — gpt-image-2
4.5 Генерация логотипов
Сильные логотипы получаются из чётких брендовых ограничений и простоты. Опишите характер бренда и сценарий использования, затем попросите чистый оригинальный знак с сильной формой, сбалансированным негативным пространством и масштабируемостью.
Параметр n задаёт число вариаций для генерации.
prompt = """
Создай оригинальный, не нарушающий чужих прав логотип для компании Field & Flour — местной пекарни.
Логотип должен ощущаться тёплым, простым и вневременным. Используй чистые векторные формы, сильный силуэт и сбалансированное негативное пространство.
Отдавай предпочтение простоте, а не детализации, чтобы он читался и в маленьком, и в большом размере. Плоский дизайн (flat design), минимум штрихов, без градиентов, если они не критичны.
Однотонный фон. Один логотип по центру с большими отступами. Без водяного знака.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
n=4 # Сгенерировать 4 варианта логотипа
)
# Сохранить все 4 изображения в отдельные файлы
for i, item in enumerate(result.data, start=1):
image_base64 = item.b64_json
image_bytes = base64.b64decode(image_base64)
with open(f"../../images/output_images/logo_generation_{i}_gpt-image-2.png", "wb") as f:
f.write(image_bytes)
Сгенерированный логотип пекарни Field & Flour (вариант 1) — gpt-image-2
4.6 Генерация рекламы
Реклама получается лучше, когда промпт написан как креативный бриф, а не как чисто технический спек изображения. Опишите бренд, аудиторию, культуру, концепт, композицию и точный текст — и дайте модели принять вкусовые креативные решения внутри этих рамок. Это полезно для ранней проработки кампании: модель интерпретирует сигналы аудитории, выводит арт-дирекшен и предлагает детали, благодаря которым реклама выглядит продуманной, а не просто отрендеренной.
Для более сильного результата включайте в один промпт позиционирование бренда, желаемый вайб, целевую аудиторию, сцену и слоган. Если текст должен быть на изображении, приводите его дословно в кавычках и просите чистую, читаемую типографику.
prompt = """
Сделай крутой, попадающий в культуру рекламный/фэшн-кадр для бренда Thread.
Это модный молодой уличный бренд. На рекламе компания друзей вместе тусуется со слоганом \"Yours to Create\".
Сделай так, чтобы это выглядело как отполированный кампейн-кадр для молодёжной streetwear-аудитории: стильно, современно, энергично и со вкусом.
Используй чистую композицию, сильное цветовое решение, естественные позы и приёмы премиальной фэшн-фотографии.
Отрисуй слоган ровно один раз, чётко и читаемо, встроенным в макет рекламы. Без лишнего текста, без водяных знаков, без посторонних логотипов.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "thread_ad_gpt-image-2.png")
Рекламный кадр бренда Thread со слоганом «Yours to Create» — gpt-image-2
4.7 История → комикс
Для генерации комикса из истории определите нарратив как последовательность чётких визуальных «битов» — по одному на панель. Держите описания конкретными и ориентированными на действие, чтобы модель перевела историю в читаемые, хорошо темпированные панели.
prompt = """
Создай короткий вертикальный комикс-рилс из 4 одинаковых по размеру панелей.
Панель 1: Хозяин выходит через входную дверь. Питомец в кадре окна позади, маленький на фоне стекла, глаза широко раскрыты, лапы прижаты высоко, дом внезапно затих.
Панель 2: Дверь защёлкивается. Тишина прерывается. Питомец медленно поворачивается к пустому дому, поза меняется, в глазах вспыхивают возможности.
Панель 3: Дом преобразился. Питомец развалился на диване как хозяин жизни, рядом крошки, солнечный свет прорезает комнату как прожектор.
Панель 4: Дверь открывается. Питомец идеально сидит у входа, бдительный и собранный, будто ничего не было.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "comic_reel-gpt-image-2.png")
Вертикальный комикс из 4 панелей про питомца — gpt-image-2
4.8 UI-макеты
UI-макеты получаются лучше, когда вы описываете продукт так, будто он уже существует. Фокусируйтесь на макете, иерархии, отступах и реальных элементах интерфейса и избегайте языка концепт-арта, чтобы результат выглядел как рабочий, выпущенный интерфейс, а не дизайн-набросок.
prompt = """
Создай реалистичный UI-макет (mockup) мобильного приложения для местного фермерского рынка.
Покажи сегодняшний рынок: простой хедер, короткий список продавцов с маленькими фото и категориями, небольшой блок «Сегодняшние спецпредложения» и базовую информацию о локации и часах работы.
Сделай его практичным и удобным. Белый фон, сдержанные природные акцентные цвета, чёткая типографика, минимум декора.
Должно выглядеть как настоящее, хорошо спроектированное, красивое приложение для маленького локального рынка.
Помести UI-макет в рамку iPhone.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "ui_farmers_market_gpt-image-2.png")
UI-макет приложения фермерского рынка в рамке iPhone — gpt-image-2
4.9 Научные / образовательные визуалы
Научные и образовательные визуалы отлично подходят для биологии, химии, школьных объяснялок, плоских систем научных иконок, диаграмм и обучающих ассетов. Промптите их как бриф по инструкционному дизайну: задайте аудиторию, учебную цель, визуальный формат, нужные подписи и научные ограничения. Для лучшего результата просите чистую плоскую визуальную систему с единым стилем иконок, понятными стрелками, читаемыми подписями и достаточным белым пространством.
Когда важна точность, перечисляйте нужные компоненты явно и говорите, чего быть не должно. Для плотных подписей, диаграмм и ассетов для слайдов/курсов используйте quality="high".
prompt = """
Создай простую биологическую диаграмму с заголовком \"Cellular Respiration at a Glance\" для старшеклассников.
Покажи, как глюкоза превращается в энергию внутри клетки. Включи гликолиз, цикл Кребса и цепь переноса электронов.
Соедини шаги стрелками и подпиши основные молекулы: glucose, pyruvate, ATP, NADH, FADH2, CO2, O2 и H2O.
Сделай это похожим на чистую учебную раздатку или слайд: белый фон, простые иконки, понятные подписи, легко читаемый текст.
Избегай мелкого текста, лишнего декора и всего, что усложняет понимание диаграммы.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1536x1024",
quality="high",
)
save_image(result, "scientific_educational_cellular_respiration_gpt-image-2.png")
Учебная диаграмма «Cellular Respiration at a Glance» — gpt-image-2
4.10 Слайды, диаграммы, графики и продуктивные изображения
Продуктивные визуалы получаются лучше, когда промпт написан как спек артефакта, а не как просьба нарисовать иллюстрацию. Назовите точный дедлайвери (слайд, диаграмма процесса, график, изображение страницы), задайте холст и иерархию, дайте реальный текст или данные и опишите визуальный язык. Включайте практические ограничения: читаемая типографика, выверенные отступы, без декоративного мусора и без типичного стокового вида.
Для слайдов, графиков и диаграмм включайте цифры и подписи прямо в промпт. Используйте горизонтальный размер для дек-стиля и quality="high", когда на изображении есть мелкий текст, легенды, оси или сноски.
prompt = """
Создай один слайд питч-дека с заголовком **\"Market Opportunity\"**, который ощущается как настоящий слайд раунда Series A от стартапа из YC.
Используй чистый белый фон, современную бессерифную типографику вроде Inter и аккуратный минималистичный макет.
Слайд должен включать:
* Диаграмму TAM/SAM/SOM из концентрических кругов в приглушённых синих и серых тонах
* Конкретные правдоподобные цифры объёма рынка:
* **TAM:** $42B
* **SAM:** $8.7B
* **SOM:** $340M
* Чистый столбчатый график ниже, показывающий рост рынка с 2021 по 2026 год, с лёгким восходящим трендом
* Мелкие сноски: \"AGI Research, 2024\" и \"Internal analysis\"
* Плейсхолдер логотипа компании в правом нижнем углу
Дизайн должен выглядеть так, будто он из дека, который реально привлёк деньги: отлично читаемый текст, чёткая иерархия данных, выверенные отступы, профессиональный стартап-стиль.
Избегай клипарта, стоковых фото, градиентов, теней, декоративных элементов и всего, что выглядит шаблонно или перегруженно.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1536x864",
quality="high",
)
save_image(result, "market_opportunity_slide_gpt-image-2.png")
5. Сценарии — Редактирование (текст + изображение → изображение)
5.1 Перенос стиля (style transfer)
Перенос стиля полезен, когда нужно сохранить визуальный язык референса (палитру, текстуру, мазки, плёночное зерно и т.д.), меняя при этом субъект или сцену. Для лучшего результата опишите, что должно остаться неизменным (стилевые сигналы) и что должно измениться (новый контент), и добавьте жёсткие ограничения вроде фона, кадрирования и «no extra elements», чтобы избежать дрейфа.
prompt = """
Используй тот же стиль, что и на входном изображении, и сгенерируй мужчину, едущего на мотоцикле, на белом фоне.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/pixels.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "motorcycle_gpt-image-2.png")
Виртуальная примерка идеальна для e-commerce превью, где критично сохранение идентичности. Ключ — явно зафиксировать человека (лицо, форму тела, позу, волосы, выражение) и разрешить менять только одежду, затем потребовать реалистичную посадку (драпировку, складки, перекрытие) плюс консистентное освещение/тени, чтобы наряд выглядел естественно надетым, а не приклеенным.
prompt = """
Отредактируй изображение, одев женщину в предоставленную одежду с изображений.
Никак не меняй её лицо, черты лица, тон кожи, форму тела, позу или идентичность.
Сохрани её точный облик, выражение, причёску и пропорции.
Замени только одежду, естественно подогнав вещи под её текущую позу и геометрию тела с реалистичным поведением ткани.
Подгони освещение, тени и цветовую температуру под оригинальное фото, чтобы наряд интегрировался фотореалистично и не выглядел приклеенным.
Не меняй фон, ракурс камеры, кадрирование и качество изображения; не добавляй аксессуары, текст, логотипы и водяные знаки.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/woman_in_museum.png", "rb"),
open("../../images/input_images/tank_top.png", "rb"),
open("../../images/input_images/jacket.png", "rb"),
open("../../images/input_images/tank_top.png", "rb"),
open("../../images/input_images/boots.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "outfit_gpt-image-2.png")
Входное фото: женщина в музее — woman_in_museum.pngКуртка — jacket.pngБотинки — boots.pngТоп — tank_top.pngРезультат виртуальной примерки — outfit_gpt-image-2.png
5.3 Рисунок → изображение (рендеринг)
Процессы «эскиз → рендер» отлично подходят для превращения грубых набросков в фотореалистичные концепты с сохранением исходного замысла. Относитесь к промпту как к спеку: сохраните макет и перспективу, затем добавьте реализм, указав правдоподобные материалы, освещение и окружение. Включайте «do not add new elements/text», чтобы избежать вольных переинтерпретаций.
prompt = """
Преврати этот рисунок в фотореалистичное изображение.
Сохрани точный макет, пропорции и перспективу.
Подбери реалистичные материалы и освещение, соответствующие замыслу эскиза.
Не добавляй новых элементов или текста.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/drawings.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "realistic_valley_gpt-image-2.png")
5.4 Продуктовые мокапы (чистый фон + целостность этикетки)
Извлечение продукта и подготовка мокапов часто используются для каталогов, маркетплейсов и дизайн-систем. Успех зависит от качества краёв (чистый силуэт, без каёмки/ореолов) и целостности этикетки (текст остаётся чётким и неизменным). Для gpt-image-2 держите фон вывода непрозрачным и используйте отдельный шаг удаления фона, если нужен финальный прозрачный ассет. Если хотите реализм без перестилизации, просите лишь лёгкую полировку и, по желанию, мягкую контактную тень на однотонном фоне.
prompt = """
Извлеки продукт из входного изображения и помести его на однотонный белый непрозрачный фон.
Результат: продукт по центру, чёткий силуэт, без ореолов и каёмки.
Точно сохрани геометрию продукта и читаемость этикетки.
Добавь лишь лёгкую полировку и мягкую реалистичную контактную тень.
Не меняй стиль продукта; только убери фон и слегка отполируй.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/shampoo.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
background="opaque",
)
save_image(result, "extract_product_gpt-image-2.png")
Входное фото шампуня — shampoo.pngПродукт на чистом белом фоне — extract_product_gpt-image-2.png
5.5 Маркетинговые креативы с реальным текстом на изображении
Маркетинговые креативы с реальным текстом на изображении отлично подходят для быстрой проработки рекламы, но типографике нужны явные ограничения. Давайте точный текст в кавычках, требуйте дословный рендеринг (без лишних символов) и описывайте расположение и стиль шрифта. Если точность текста несовершенна — держите промпт строгим и итерируйте: небольшие правки формулировок/макета обычно улучшают читаемость.
prompt = """
Создай реалистичный макет билборда с шампунем на фоне трассы во время заката.
Текст на билборде (ТОЧНО, дословно, без лишних символов): \"Fresh and clean\"
Типографика: жирный гротеск, высокий контраст, по центру, аккуратный кернинг.
Убедись, что текст появляется один раз и идеально читается. Без водяных знаков, без логотипов.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/shampoo.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "billboard_gpt-image-2.png")
Входное фото шампуня — shampoo.pngБилборд с текстом «Fresh and clean» — billboard_gpt-image-2.png
5.6 Смена освещения и погоды
Используется, чтобы пересобрать фото под другое настроение, сезон или время суток (например, солнечно → пасмурно, день → сумерки, ясно → снег), сохраняя композицию сцены. Ключ — менять только условия среды (направление/качество света, тени, атмосферу, осадки, влажность поверхности), сохраняя идентичность, геометрию, ракурс камеры и расположение объектов, чтобы оно читалось как то же исходное фото.
prompt = """
Сделай так, чтобы это выглядело как зимний вечер со снегопадом.
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/billboard_gpt-image-2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "billboard_winter_gpt-image-2.png")
Тот же билборд зимним вечером со снегопадом — gpt-image-2
5.7 Удаление объекта
Полезно для сторибордов, кампаний и сценариев «что если», где важно сохранение лица/идентичности. Закрепите реализм, задав приземлённый фотографический вид (естественный свет, правдоподобная детализация, без киношной цветокоррекции), и зафиксируйте, что нельзя менять в субъекте. Где доступно, более высокий input_fidelity помогает сохранять схожесть при крупных правках сцены.
prompt = """
Убери цветок из руки мужчины. Больше ничего не меняй.
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/man_with_blue_hat.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "man_with_no_flower_gpt-image-2.png")
Исходное фото: мужчина с цветком — man_with_blue_hat.pngТот же кадр без цветка — man_with_no_flower_gpt-image-2.png
5.8 Вставка человека в сцену
Композитинг «человек в сцене» полезен для сторибордов, кампаний и сценариев «что если», где важно сохранение лица/идентичности. Закрепите реализм, задав приземлённый фотографический вид (естественный свет, правдоподобная детализация, без киношной цветокоррекции), и зафиксируйте, что нельзя менять в субъекте. Где доступно, более высокий input_fidelity помогает сохранять схожесть при крупных правках сцены.
prompt = """
Сгенерируй максимально реалистичную динамичную сцену, где этот человек убегает от большого реалистичного бурого медведя, атакующего кемпинг.
Изображение должно выглядеть как настоящая фотография, которую кто-то мог снять, а не как чрезмерно обработанный или киношный постер.
Она в центре кадра, но смотрит в сторону от камеры, одета в туристическую одежду, на лице грязь, одежда порвана.
Она явно напугана, но сосредоточена на побеге, убегает от медведя, пока тот разносит кемпинг позади.
Кемпинг находится в Йосемитском национальном парке, с правдоподобными природными деталями.
Время суток — сумерки, естественное освещение и реалистичные цвета.
Всё должно ощущаться приземлённым, подлинным и нестилизованным, будто снято в реальный момент. Избегай киношного освещения, драматичной цветокоррекции и стилизованной композиции.
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/input_images/woman_in_museum.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "scene_gpt-image-2.png")
Композитинг: женщина убегает от медведя в кемпинге — gpt-image-2
5.9 Мульти-изображения и композитинг
Используется, чтобы объединить элементы из нескольких входов в одно правдоподобное изображение — отлично для процессов «вставь этот объект/человека в ту сцену» без перегенерации всего. Ключ — чётко указать, что переносить (собаку с изображения 2), куда (прямо рядом с женщиной на изображении 1) и что должно остаться неизменным (сцена, фон, кадрирование), подгоняя освещение, перспективу, масштаб и тени, чтобы композит выглядел естественно снятым на исходном фото.
prompt = """
Помести собаку со второго изображения в обстановку с изображения 1, прямо рядом с женщиной, используй тот же стиль освещения, композиции и фона. Больше ничего не меняй.
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/test_woman.png", "rb"),
open("../../images/output_images/test_woman_2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "test_woman_with_dog_gpt-image-2.png")
Изображение 1: женщина — test_woman.pngИзображение 2: собака — test_woman_2.pngРезультат композитинга: женщина с собакой — test_woman_with_dog_gpt-image-2.png
6. Дополнительные ценные сценарии
6.1 Интерьерный «свап» (точные правки)
Используется для визуализации замены мебели или декора в реальных помещениях без перерисовки всей сцены. Цель — хирургический реализм: заменить один объект, сохранив ракурс камеры, освещение, тени и окружение, чтобы правка выглядела как реальное фото, а не как редизайн.
prompt = """
На этом фото комнаты замени ТОЛЬКО белые стулья на стулья из дерева.
Сохрани ракурс камеры, освещение комнаты, тени на полу и окружающие объекты.
Оставь все остальные аспекты изображения без изменений. Фотореалистичные контактные тени и текстура ткани.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/kitchen.jpeg", "rb"),
],
prompt=prompt,
size="1536x1024",
quality="medium",
)
save_image(result, "kitchen-chairs_gpt-image-2.png")
Результат: деревянные стулья вместо белых — kitchen-chairs_gpt-image-2.pngИсходное фото комнаты — kitchen.jpg
6.2 3D pop-up праздничная открытка (продуктовый мок)
Идеально для сезонных маркетинговых концептов и превью печати. Акцент на тактильном реализме — слои бумаги, волокна, сгибы и мягкий студийный свет — чтобы результат читался как сфотографированный физический продукт, а не плоская иллюстрация.
scene_description = (
"уютная рождественская сцена со старым плюшевым мишкой, сидящим внутри памятной коробки, "
"немного потёртый мех, мягкие стежки-починки, у окна, за которым падает снег. "
"Сцена намекает, что ребёнок вырос, но воспоминания остались."
)
short_copy = "Merry Christmas — some memories never fade."
prompt = f"""
Создай иллюстрацию рождественской открытки.
Сцена: {scene_description}
Настроение: тёплое, ностальгическое, нежное, эмоциональное.
Стиль: премиальная фотография праздничной открытки, мягкий кинематографичный свет, реалистичные текстуры, малая глубина резкости, аккуратное боке, композиция печатного качества.
Ограничения:
- Только оригинальная работа
- Без торговых марок
- Без водяных знаков
- Без логотипов
Включи ТОЛЬКО этот текст открытки (дословно): \"{short_copy}\"
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "christmas_holiday_card_teddy_gpt-image-2.png")
Рождественская открытка с плюшевым мишкой и текстом «Merry Christmas — some memories never fade.» — gpt-image-2
Используется для ранней проработки мерча и питч-визуалов. Фокус на приёмах премиальной продуктовой фотографии (материалы, упаковка, чёткость печати) при сохранении оригинальности дизайна. Хорошо подходит для быстрой проверки нескольких вариантов персонажа или упаковки.
# ---- Входные данные ----
character_description = (
"винтажная игрушка-самолётик с пропеллером, со скруглёнными крыльями, "
"вращающимся пропеллером спереди, слегка потёртыми краями краски, "
"классическими детскими пропорциями, задуманная как ностальгический праздничный коллекционный предмет"
)
short_copy = "Christmas Memories Edition"
# ---- Промпт ----
prompt = f"""
Создай коллекционную фигурку: {character_description}, в блистерной упаковке.
Концепт: ностальгический праздничный коллекционный предмет, вдохновлённый простыми игрушечными самолётиками, в которые дети играли на зимних каникулах. Вызывает тепло, воображение и детское чудо.
Стиль: премиальная фотография игрушки, реалистичные текстуры пластика и крашеного металла, студийный свет, малая глубина резкости, чёткая печать этикетки, презентация уровня премиального ретейла.
Ограничения:
- Только оригинальный дизайн
- Без торговых марок
- Без водяных знаков
- Без логотипов
Включи ТОЛЬКО этот текст упаковки (дословно): \"{short_copy}\"
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "christmas_collectible_toy_airplane_gpt-image-2.png")
6.4 Иллюстрации детской книги с консистентностью персонажа (мульти-изображения)
Создано для конвейеров многостраничной иллюстрации, где дрейф персонажа недопустим. Переиспользуемый «якорь персонажа» обеспечивает визуальную непрерывность между сценами, позами и страницами, допуская вариации окружения и нарратива.
1️⃣ Якорь персонажа — задаём переиспользуемого главного героя
Цель: зафиксировать внешность, пропорции, наряд и тон персонажа.
prompt = """
Создай иллюстрацию детской книги, представляющую главного героя.
Персонаж: юный герой в книжном стиле, вдохновлённый маленьким лесным разбойником, в простой зелёной тунике с капюшоном, мягких коричневых сапожках и с небольшой поясной сумкой. У персонажа доброе выражение, мягкие глаза, храбрый, но тёплый нрав. Несёт маленький деревянный лук, который используется только чтобы помогать, а не вредить.
Тема: персонаж защищает и спасает маленьких лесных зверей — белок, птиц, кроликов.
Стиль: иллюстрация детской книги, ручная акварель, мягкие контуры, тёплые землистые цвета, причудливо и дружелюбно. Пропорции под книжки с картинками (чуть увеличенная голова, выразительное лицо).
Ограничения:
- Оригинальный персонаж (без защищённых авторским правом персонажей)
- Без текста
- Без водяных знаков
- Однотонный лесной фон, чтобы чётко показать персонажа
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "childrens_book_illustration_1_gpt-image-2.png")
Якорь персонажа: юный лесной герой — childrens_book_illustration_1_gpt-image-2.png
2️⃣ Продолжение истории — переиспользуем персонажа, развиваем нарратив
Цель: тот же персонаж, новая сцена + действие. Внешность персонажа должна остаться неизменной.
prompt = """
Продолжи историю детской книги с тем же персонажем.
Сцена: тот же юный лесной герой нежно помогает испуганной белке выбраться из упавшего дерева после зимней бури. Персонаж опускается на колени рядом с белкой, успокаивая её.
Консистентность персонажа:
- Та же зелёная туника с капюшоном
- Те же черты лица, пропорции и цветовая палитра
- Тот же нежный, героический характер
Стиль: акварельная иллюстрация детской книги, мягкий свет, снежный лес, тёплое и уютное настроение.
Ограничения:
- Не редизайнить персонажа
- Без текста
- Без водяных знаков
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/output_images/childrens_book_illustration_1_gpt-image-2.png", "rb"), # изображение из шага 1
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "childrens_book_illustration_2_gpt-image-2.png")
Тот же персонаж помогает белке после зимней бури — childrens_book_illustration_2_gpt-image-2.png
Заключение
В этом гайде показано, как использовать модели генерации gpt-image для построения высококачественных, управляемых процессов генерации и редактирования изображений, которые держат уровень в реальном продакшене. Главные инструменты контроля — структура промпта, явные ограничения и небольшие итеративные изменения; именно они управляют реализмом, макетом, точностью текста и сохранением идентичности. Гайд покрывает и генерацию, и редактирование — от инфографики, фотореализма, UI-макетов и логотипов до перевода, переноса стиля, виртуальной примерки, композитинга и смены освещения. Сквозная мысль — чётко отделять то, что должно меняться, от того, что обязано оставаться неизменным, и повторять список инвариантов на каждой итерации, чтобы предотвратить дрейф. Также подчёркнуто, как настройки quality и input_fidelity позволяют осознанно балансировать между задержкой и визуальной точностью под конкретный сценарий. Вместе эти примеры образуют практичный воспроизводимый плейбук для применения моделей gpt-image в продакшен-процессах работы с изображениями.
🖼️
Иллюстрации к каждому примеру (сгенерированные изображения и входные референсы) встроены в соответствующие разделы выше. Полный оригинал с notebook-кодом доступен по ссылкам ниже.
Если вы выстраиваете собственный процесс генерации и редактирования изображений — обложки, реклама, UI-моки, иллюстрации, — главное здесь не «волшебный» промпт, а повторяемый контур с понятными ограничениями и предсказуемым результатом. Это одинаково полезно дизайнерам и продуктовым командам, которые хотят поставить картиночные пайплайны на поток.
Если захотите обсудить, как это применить у себя или в команде — пишите в Telegram @pimenov
Google выпустил Nano Banana 2 — обновлённую модель генерации изображений, которая объединяет скорость Flash с качеством Pro. Разбираю ключевые улучшения и показываю, как это работа…
Anthropic выпустили подробный гайд по работе с Claude Code — и большинство его проигнорировали. Рассказываю, как превратить документацию в персональный курс за один промпт.
SpaceX отдаёт Anthropic всю мощность Colossus 1, лимиты Claude растут, а на фоне суда Маска с OpenAI это выглядит как публичный жест в сторону Альтмана.
Мы используем cookie и аналитические сервисы Яндекс.Метрика, Top.Mail.Ru и Umami для анализа посещаемости и улучшения сайта. Продолжая пользоваться сайтом, вы соглашаетесь с
Политикой обработки персональных данных.